
(fyi, here’s the code for everything I built below, you can play around with it in Patterns AI Studio as well.)
When I was at Square and the team was smaller we had a dreaded “analytics on-call” rotation. It was strictly rotated on a weekly basis, and if it was your turn up you knew you would get very little “real” work done that week and spend most of your time fielding ad-hoc questions from the various product and operations teams at the company (SQL monkeying, we called it). There was cutthroat competition for manager roles on the analytics team and I think this was entirely the result of managers being exempted from this rotation -- no status prize could rival the carrot of not doing on-call work.
So, the idea that something like analytics on-call could be entirely replaced by a next-token optimizer like GPT-3 has been an idea I’ve been excited to try for a long time now. I finally got a chance to sit down and try it out this week.
We’re about to kick off our fundraising process, so I to test the idea I attempted to build a free-form question answering analytics bot on top of the Crunchbase data set of investors, companies, and fundraising rounds. I call it CrunchBot.
Read on to get the details, but here is a quick example of it getting a simple thing exactly right:
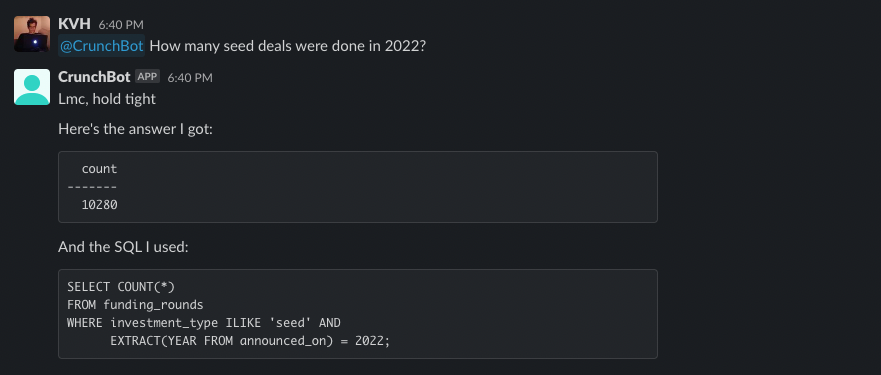
And an example of it getting something more complex exactly right:
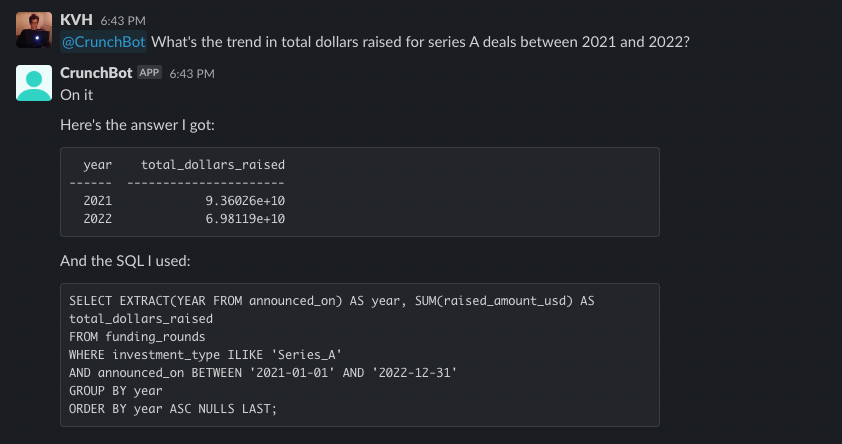
And an example of it getting something complex terrifically wrong (watch your join conditions davinci-003!):
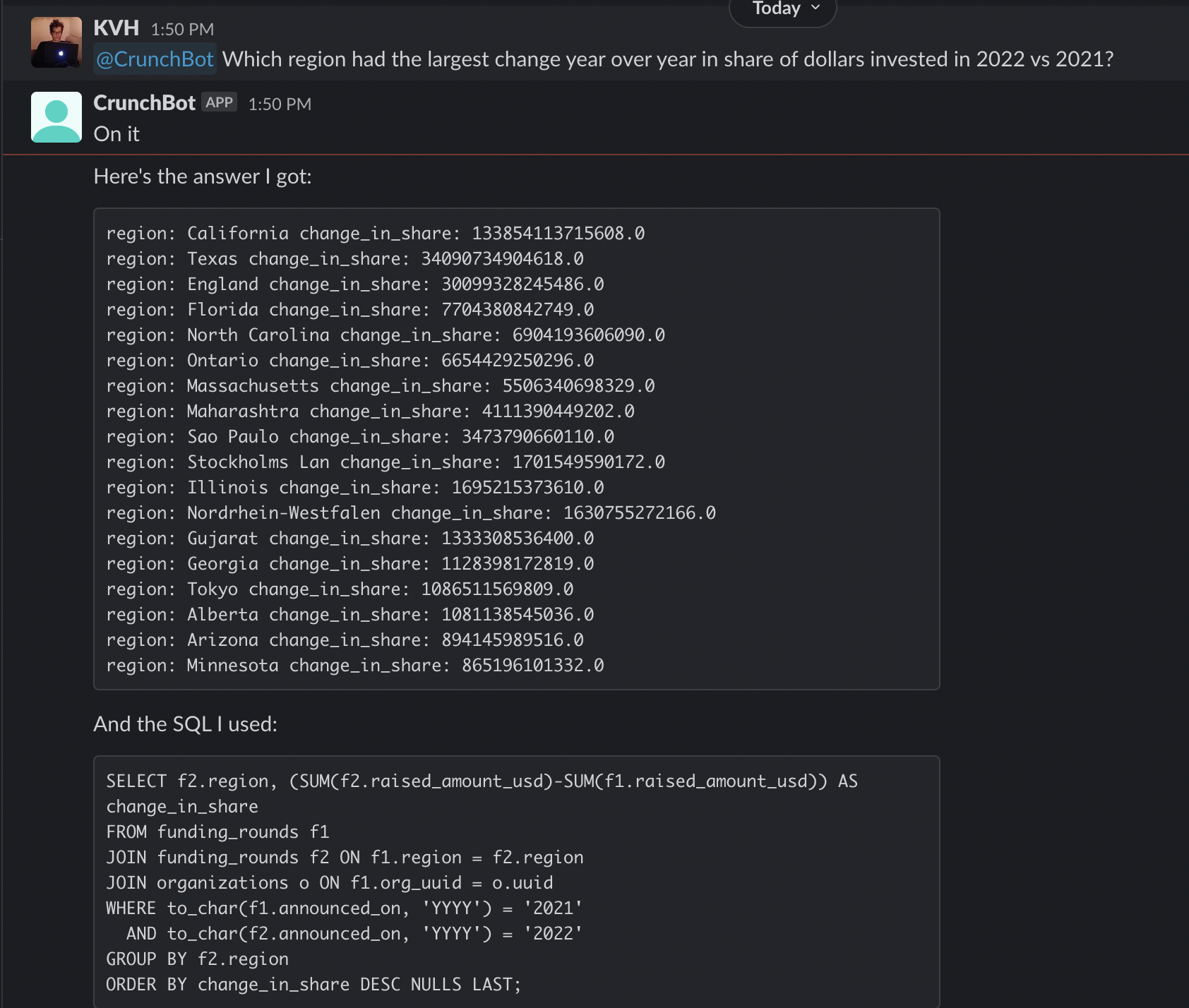
And something of medium complexity mostly right (it’s so close here, needs an ilike instead of like, which it messed up despite a specific prompt telling it to watch out for this mistake):
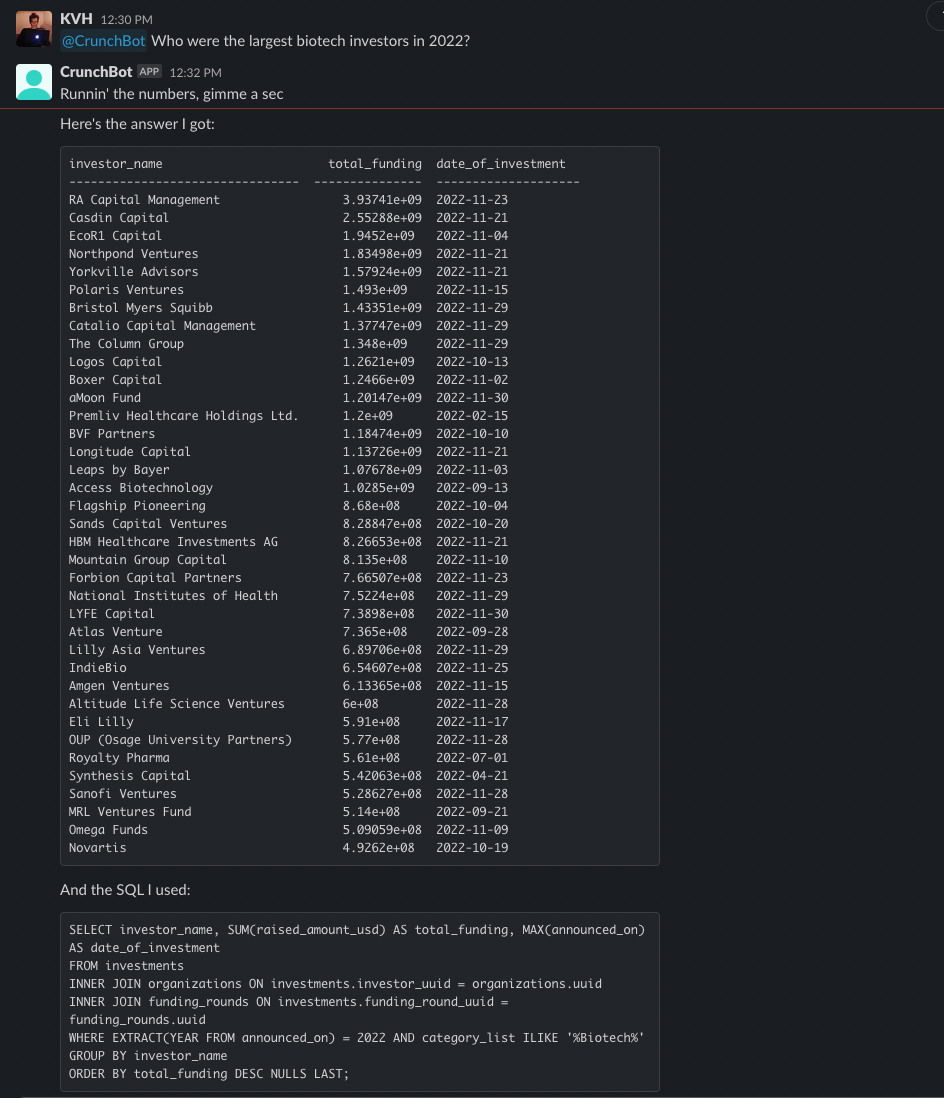
Overall I was dumbfounded with the quality of the results. LLMs are a continual source of blown minds, but this is shockingly close to replacing an entire role at companies with only a few hours of effort.
How I built it
My plan was to build it in Patterns Studio. There were mostly four parts
- Build the prompt from
- user’s question
- schemas and sample data of the available tables
- clear directions
- Run it through various GPT models and get 5+ completions of raw SQL
- Execute the SQL against the relevant tables, pick the best result
- Hook it up to a Slack bot
By the end I had a much more complex pipeline as I kept quickly finding prompt improvements. Specifically the SQL generation and execution part became a loop of:
- Generate a candidate query
- Quality check the SQL with GPT itself, asking it to spot common errors (NULLS LAST, for instance) and produce a correct version of the query
- Run the SQL against the tables
- If there was an error or no result, ask GPT to fix the query to produce a correct result and repeat the loop
- Otherwise, return the result
This led to completion chains of over 20 calls to GPT for a single user question. There feels like some logarithmic improvement in each GPT call — you can continue to add more context and checks with every completion, exploring different versions and iterating on the result. This is the same process that a junior analyst would use to arrive at the answer, in this case it takes 15 seconds and costs $1 in credits vs $50 and 1 hour for the analyst. You have a LOT of leeway there to use even more crazy prompt pipelines before the ROI gets bad.
Anyways, here’s the step-by-step of how I built it. You can follow along in this template app on Patterns that has all the code (no data it in, Crunchbase is a proprietary data set — reach out kvh@patterns.app if you are interested in exploring this specific data set).
1. Get the Crunchbase data
The full Crunchbase dataset includes 2.4m organizations and 510k funding rounds. We ingest this via the full CSV dump every 24 hours into our postgres instance. For this analysis we restricted it to three tables: organizations, funding_rounds, and investments.
2. Build the initial prompt
The initial SQL generation prompt includes three basic elements: a summary of the tables and data available to query, the user’s question, and a prompt asking GPT to write a correct Postgres query. Here’s the exact template we used:
prompt = f"""{tables_summary}
As a senior analyst, given the above schemas and data, write a detailed and correct Postgres sql query to answer the analytical question:
"{question}"
Comment the query with your logic."""
Which results in this full prompt, for example:
Schema for table: organizations
uuid Text
name Text
roles Text
country_code Text
region Text
city Text
status Text
short_description Text
category_list Text
num_funding_rounds Float
total_funding_usd Float
founded_on Date
employee_count Text
email Text
primary_role Text
Data for table: organizations:
uuid name roles \
0 ac323097-bdd0-4507-9cbc-6186e61c47a5 Bootstrap Enterprises company
1 717ce629-38b6-494d-9ebf-f0eeb51506f8 Campanizer company
2 c8cbaa69-c9db-44e2-9ffa-eb4722a62fe3 Cambr company
3 5ab1ae3d-c3a1-4268-a532-b500d3dd6182 CallMeHelp company
4 143f840b-551c-4dbd-a92b-0804d654b5cf California Cannabis Market company
country_code region city status \
0 <NA> <NA> <NA> operating
1 USA Colorado Boulder operating
2 USA New York New York operating
3 GBR Stockport Stockport operating
4 USA California San Francisco closed
short_description \
0 Bootstrap Enterprises is an organic waste mana...
1 Campanizer organizes schedule and coordinates ...
2 Cambr enables companies to build and scale fin...
3 CallMeHelp provides early warning and care ove...
4 California Cannabis Market is an information t...
category_list num_funding_rounds \
0 Consulting,Organic,Waste Management NaN
1 Information Technology,Scheduling NaN
2 Banking,Financial Services NaN
3 Fitness,Health Care,Wellness NaN
4 B2B,Information Services,Information Technology NaN
total_funding_usd founded_on employee_count email \
0 NaN NaT unknown <NA>
1 NaN 2017-01-01 1-10 hello@campanizer.com
2 NaN NaT unknown sales@cambr.com
3 NaN 2017-01-01 1-10 <NA>
4 NaN 2018-01-01 1-10 <NA>
primary_role
0 company
1 company
2 company
3 company
4 company
Schema for table: investments
uuid Text
name Text
funding_round_uuid Text
funding_round_name Text
investor_uuid Text
investor_name Text
investor_type Text
is_lead_investor Boolean
Data for table: investments:
uuid \
0 524986f0-3049-54a4-fa72-f60897a5e61d
1 6556ab92-6465-25aa-1ffc-7f8b4b09a476
2 0216e06a-61f8-9cf1-19ba-20811229c53e
3 dadd7d86-520d-5e35-3033-fc1d8792ab91
4 581c4b38-9653-7117-9bd4-7ffe5c7eba69
name \
0 Accel investment in Series A - Meta
1 Greylock investment in Series B - Meta
2 Meritech Capital Partners investment in Series...
3 Trinity Ventures investment in Series B - Phot...
4 Founders Fund investment in Series A - Geni
funding_round_uuid funding_round_name \
0 d950d7a5-79ff-fb93-ca87-13386b0e2feb Series A - Meta
1 6fae3958-a001-27c0-fb7e-666266aedd78 Series B - Meta
2 6fae3958-a001-27c0-fb7e-666266aedd78 Series B - Meta
3 bcd5a63d-ed99-6963-0dd2-e36f6582f846 Series B - Photobucket
4 60e6afd9-1215-465a-dd17-0ed600d4e29b Series A - Geni
investor_uuid investor_name \
0 b08efc27-da40-505a-6f9d-c9e14247bf36 Accel
1 e2006571-6b7a-e477-002a-f7014f48a7e3 Greylock
2 8d5c7e48-82da-3025-dd46-346a31bab86f Meritech Capital Partners
3 7ca12f7a-2f8e-48b4-a8d1-1a33a0e275b9 Trinity Ventures
4 fb2f8884-ec07-895a-48d7-d9a9d4d7175c Founders Fund
investor_type is_lead_investor
0 organization True
1 organization True
2 organization True
3 organization <NA>
4 organization True
Schema for table: funding_rounds
uuid Text
region Text
city Text
investment_type Text
announced_on Date
raised_amount_usd Float
post_money_valuation_usd Float
investor_count Float
org_uuid Text
org_name Text
lead_investor_uuids Text
Data for table: funding_rounds:
uuid region city \
0 8a945939-18e0-cc9d-27b9-bf33817b2818 California Menlo Park
1 d950d7a5-79ff-fb93-ca87-13386b0e2feb California Menlo Park
2 6fae3958-a001-27c0-fb7e-666266aedd78 California Menlo Park
3 bcd5a63d-ed99-6963-0dd2-e36f6582f846 Colorado Denver
4 60e6afd9-1215-465a-dd17-0ed600d4e29b California West Hollywood
investment_type announced_on raised_amount_usd post_money_valuation_usd \
0 angel 2004-09-01 500000.0 NaN
1 series_a 2005-05-01 12700000.0 98000000.0
2 series_b 2006-04-01 27500000.0 502500000.0
3 series_b 2006-05-01 10500000.0 NaN
4 series_a 2007-01-17 NaN 10000000.0
investor_count org_uuid org_name \
0 4.0 df662812-7f97-0b43-9d3e-12f64f504fbb Meta
1 4.0 df662812-7f97-0b43-9d3e-12f64f504fbb Meta
2 5.0 df662812-7f97-0b43-9d3e-12f64f504fbb Meta
3 2.0 f53cb4de-236e-0b1b-dee8-7104a8b018f9 Photobucket
4 1.0 4111dc8b-c0df-2d24-ed33-30cd137b3098 Geni
lead_investor_uuids
0 3f47be49-2e32-8118-01a0-31685a4d0fd7
1 b08efc27-da40-505a-6f9d-c9e14247bf36
2 e2006571-6b7a-e477-002a-f7014f48a7e3,8d5c7e48-...
3 <NA>
4 fb2f8884-ec07-895a-48d7-d9a9d4d7175c
As a senior analyst, given the above schemas and data, write a detailed and correct Postgres sql query to answer the analytical question:
"Who were the largest biotech investors in 2022?"
Comment the query with your logic.
3. Double check the query
I found GPT made some common mistakes over and over again (the same ones any analyst would make), so I gave it a specific prompt to review each query and fix any bugs before doing anything else:
prompt = f"""{query.sql}
Double check the Postgres query above for common mistakes, including:
- Remembering to add `NULLS LAST` to an ORDER BY DESC clause
- Handling case sensitivity, e.g. using ILIKE instead of LIKE
- Ensuring the join columns are correct
- Casting values to the appropriate type
Rewrite the query here if there are any mistakes. If it looks good as it is, just reproduce the original query."""
4. Run the generated SQL against the database, fix any errors
Next we try to run the SQL against the database. If it produces a result, we store the result and query. If it produces no result or an error, we ask GPT to fix the SQL:
error_prompt = f"""{query.sql}
The query above produced the following error:
{query.error}
Rewrite the query with the error fixed:"""
no_result_prompt = f"""{query.sql}
The query above produced no result. Try rewriting the query so it will return results:"""
Here’s an example of this step working well, with the following query. Can you spot the error?
SELECT org_category,
SUM(CASE WHEN YEAR(announced_on) = 2021 THEN raised_amount_usd ELSE 0 END) as 2021_investments,
SUM(CASE WHEN YEAR(announced_on) = 2022 THEN raised_amount_usd ELSE 0 END) as 2022_investments,
SUM(CASE WHEN YEAR(announced_on) = 2022 THEN raised_amount_usd ELSE 0 END) - SUM(CASE WHEN YEAR(announced_on) = 2021 THEN raised_amount_usd ELSE 0 END) as diff_investments
FROM organizations o JOIN funding_rounds f ON o.uuid = f.org_uuid
GROUP BY org_category
ORDER BY diff_investments DESC NULLS LAST
LIMIT 1;
Syntax error:
ERROR: syntax error at or near "2021_investments"
LINE 2: ..._on) = 2021 THEN raised_amount_usd ELSE 0 END) as 2021_inves...
Which was then fixed with this new query:
SELECT org_category,
SUM(CASE WHEN YEAR(announced_on) = 2021 THEN raised_amount_usd ELSE 0 END) as investments_2021,
SUM(CASE WHEN YEAR(announced_on) = 2022 THEN raised_amount_usd ELSE 0 END) as investments_2022,
SUM(CASE WHEN YEAR(announced_on) = 2022 THEN raised_amount_usd ELSE 0 END) - SUM(CASE WHEN YEAR(announced_on) = 2021 THEN raised_amount_usd ELSE 0 END) as diff_investments
FROM organizations o JOIN funding_rounds f ON o.uuid = f.org_uuid
GROUP BY org_category
ORDER BY diff_investments DESC NULLS LAST
LIMIT 1;
5. Repeat N times
Repeat the above completion loop as many times as we want to get a set of queries and results. I chose to stop this loop once I got a result that matched a previous result, or I hit my limit of max tries (5 in this case).
6. Build the Slack bot
I used the off-the-shelf Patterns template for Slack bots and hooked it up. I added a second slack node for acknowledging the original Slack mention quickly, since the full GPT pipeline can take 20 seconds plus.
Conclusion
It seems like there’s almost no limit to how good GPT could get at this. The remaining failure modes were ones of either missing context or not enough iterative debugging (the kind that is the beating heart of any analytics endeavor). For instance, GPT had to guess the exact names and spellings of categories or company names when answering questions. If it was allowed to run some “research” queries first, it could have been able to build enough context for a final prompt and query to get to the right answer. Playing around with GPT at this level you get the feeling that “recursive GPT” is very close to AGI. You could even ask GPT to reinforcement learn itself, adding new prompts based on fixes to previous questions. Of course, who knows what will happen to all this when GPT-4 drops.