
In the past, when I needed any type of product information like the best phone or cloud provider, I would often turn to Google. Many people do the same, but I've noticed that over time, Google has become more focused on turning a profit which litters my search results with paid advertisements that don’t actually answer my question. A friend suggested to instead append “Reddit” to the end of every Google search… this simple change helped me find more relevant and accurate results.
This inspired me to create a custom newsletter for any subreddit to send me Reddit's "thoughts" every day. Here's how I did it and here's a link to clone the public app and run your own newsletter!
Getting data from Reddit
To begin, I attempted to collect data from Reddit. I initially thought it would be easy, as Reddit is a modern technology company, and assumed I could access their data through an API with the proper credentials. However, I found that I needed to create a developer account and provide my username and password. In order to make it easy for others to replicate my application, I decided to use web scraping as a method to collect the data instead.
At first I looked at the "new" reddit site (reddit.com), only to find it is dynamically generated CSS and is thus hard to pin down from a web scraping perspective.
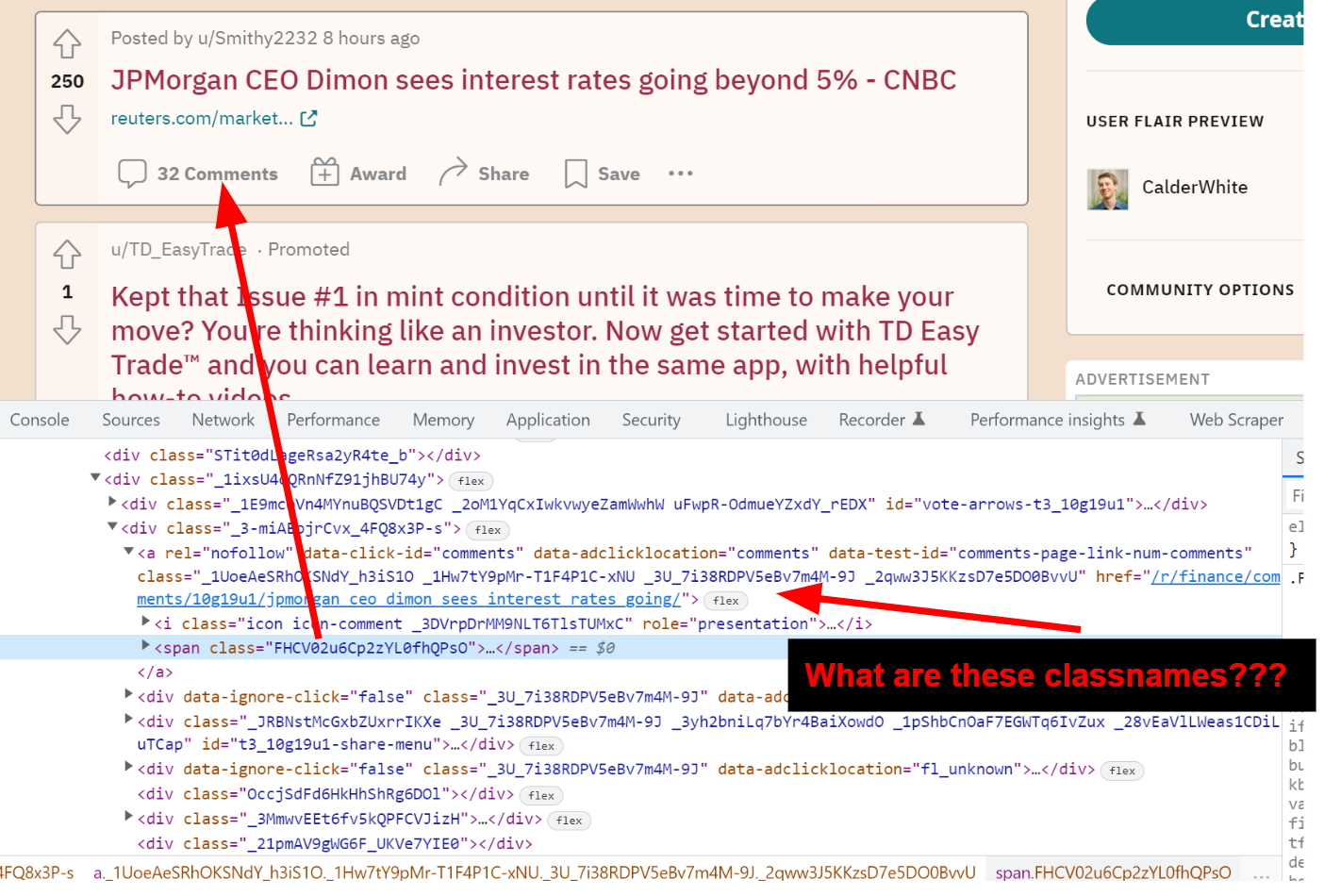
However, in finding this I realized that dynamic site generation is a relatively new phenomenon and that in the earlier days of the internet people used their actual internet class names and ids to style and organize their web pages. So I turned to old.reddit.com, and sure enough, it was easily scrapable with telling class names such as ".title" and ".entry".
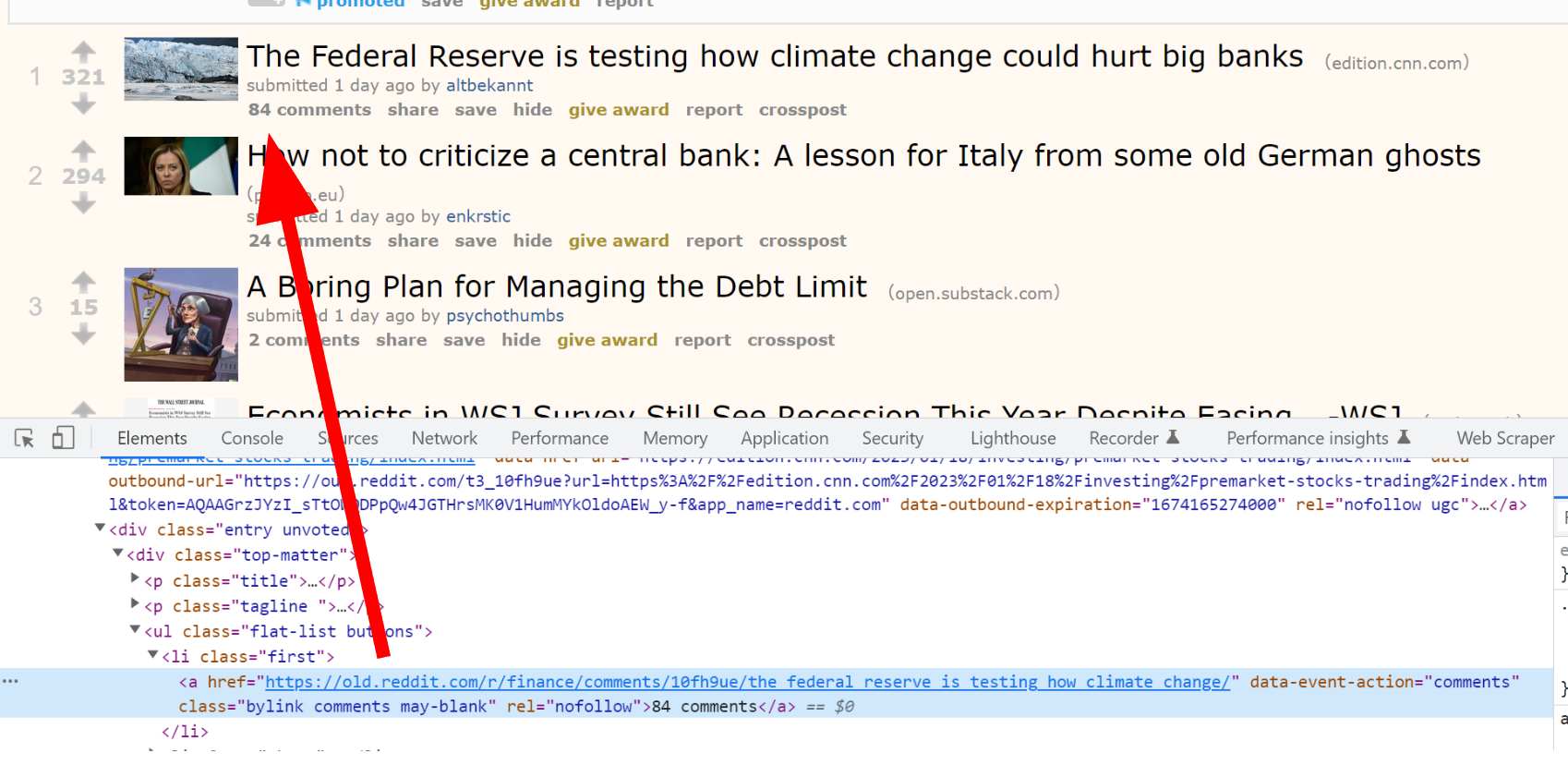
I broke out Python’s BeautifulSoup and got to work writing a web scraping script in conjunction with the requests module. Another slight problem I encountered was that reddit did have some basic bot protection in their requests, but that was easily circumvented by copying valid requests headers & cookies and adding them to my GET request to make it look like it was coming from a real browser.
Determining Reddit's "Opinion" with OpenAI
To generate Reddit’s "opinion" on posts, I decided to take the comments as one contiguous block of text and summarize it with OpenAI’s Tl;dr feature. This way I left the tough decisions about which comments were more important up to OpenAI’s LLM instead of hard coded logic. One way this could be expanded is if I incorporated the votes of comments into how my summaries are generated, for example filtering out comments whose votes are too low.
The way Tl;dr works is that you simply insert any text up to a token limit and then append the string "Tl;dr" to it. Run that through OpenAI’s completion engine and it will output its best summary of the information provided. One limitation of this is that there is an output token limit of 60 tokens, which means that the summaries OpenAI provides will be quite small. Another tricky limitation was the input token limit which is set at 4000 tokens. Not only did many post’s comment threads exceed this limit, but calculating the exact ratio of character limits to token limits is a bit difficult. OpenAI does not actually provide you with resources to determine what is and is not a token to them. However, they do provide approximations on their website.

[source: https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them ]
Their approximation is that 1 token is roughly 4 characters. To stay in the safe zone, I approximated that 1 token is 3 characters, and multiplied the 4000 token limit by the 3 character ratio to give myself a character limit for OpenAI’s completion engine. Additionally, I implemented chunking to allow summarization of all of the comments. I simply chunked the input by the character limit, summmarized the chunks individually and then concatonated the summaries into one master summary. There is room for expansion in this strategy however. One way to achieve this may be to summarize smaller chunks of the comments and then rerun those concatonated summaries back into OpenAI for your final summary. This is essentially recursive summarizing, which I fear may cause issues due to residual errors present in OpenAI’s LLM, but if the model is good enough you might be able to get away with one iteration. This provides the added benefit of cohere text flow, instead of disjoint summaries strung together. As mentioned before, another way summarization could be improved is by filtering for the more popular opinions represented in higher vote posts instead of weighting all comments equally.
Extra Features from Patterns :)
Easy to read crons! Patterns allowed me to set my own crong and also told me in plain english what the schedule was. This saved me the hassle of going to crontab.guru every single time I want to set a crontab.
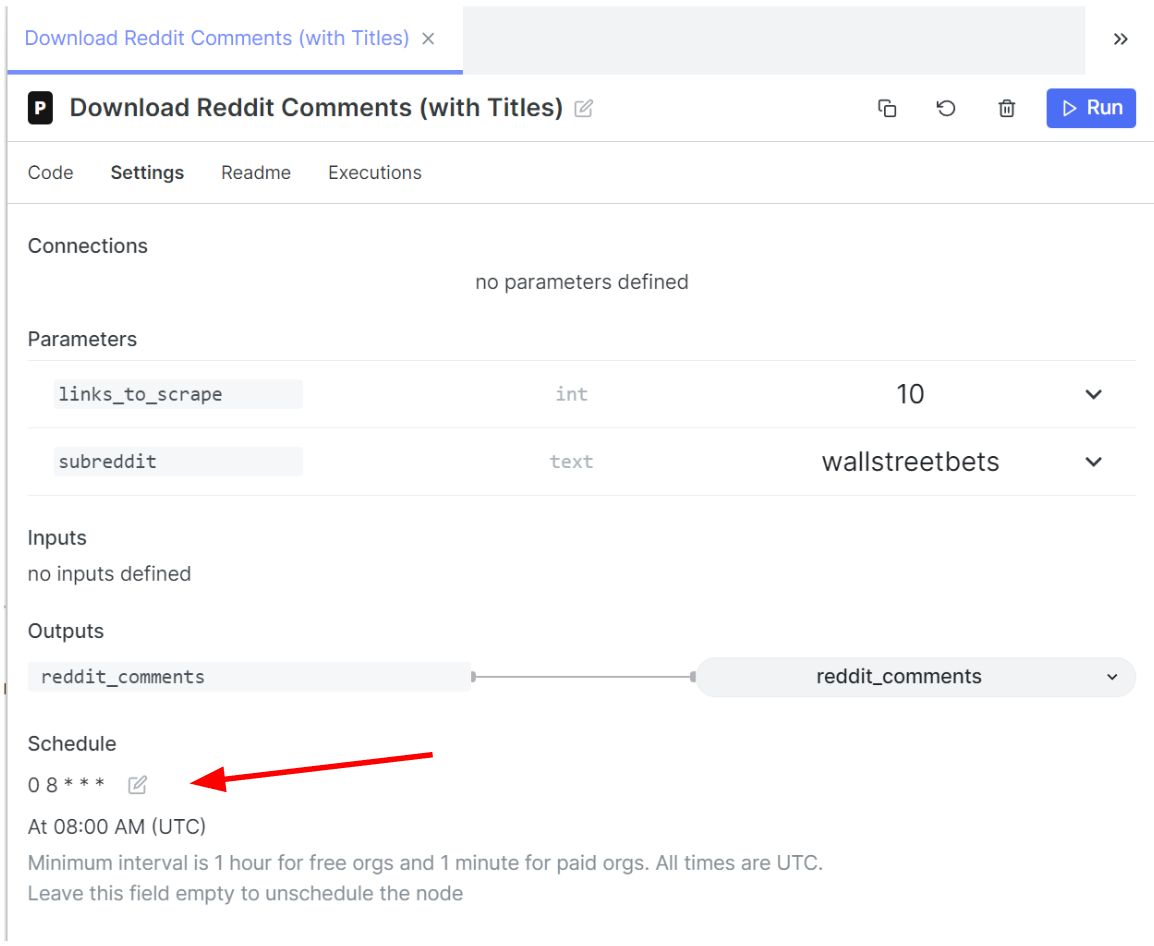
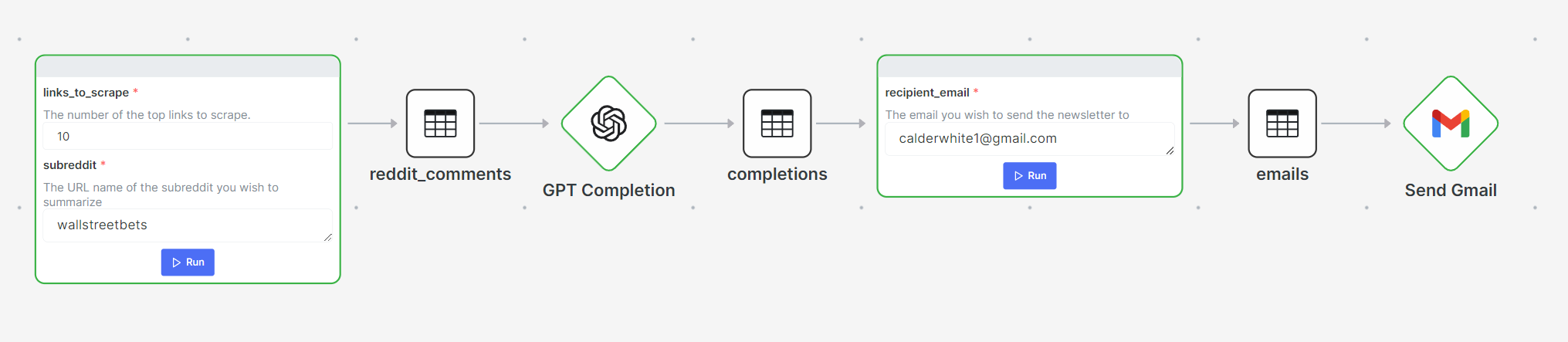
Some nice built in features Patterns allowed me to have was the node form view option. This way I could easily see what my parameters were and quickly change them. For example, the subreddit or the email I was sending my newsletter to.
It was also nice to be able to use the OpenAI completion component as well as the "Send email with Gmail" component so I didn’t have to write all of the code to interface with these APIs. It allowed me to focus on what I was interested in, which was downloading and ingesting the data from reddit.
Wrapping up
There were some really interesting results from Reddit's summaries. Although my algorithm for combining chunks from reddit comments was not perfect, the results produced were very insightful.
In wallstreetbets Reddit advised against pump and dumps

Some banter about Jamie Dimon stating the obvious:

Some good guidance on recession fears (with a bit of self promotion noise):

I was really impressed with the simplicity in summarizing the opinions with OpenAI + using the prebuilt components from patterns to glue these systems together! I think with some more tweaks you could certainly automate a newsletter and gain thousands of subscribers.
The Code
But the code! Here's a link to the public graph. Feel free to clone it and run your own newsletter!